


On the Ineffability of Sight and Sound
To what extent are the auditory applications of LLMs limited by natural language itself?


Nice idea, but is it fundamentally limited by reality?
I’ve recently come across a few interesting LLM apps that claim to produce high-fidelity music from natural language descriptions (I particularly like Suno and Google’s MusicLM). This domain isn’t that new, especially given how fast things move in LLM-land, but the quality has gotten quite good in the past year.
Still, the idea of mapping a natural language description of music to the music itself feels flawed. If you were asked to describe your favorite song, how would you do it? How would you describe the accompaniment to Mary Had a Little Lamb? Of course, you could hum or sing it; you could recite the notes. But, I’d posit that describing the song with any level of specificity using natural language alone is intractable. There are many ways to describe a given song, and you could generate many (very different sounding) songs from a description.
To be clear, I’m not making the claim that you can’t use LLMs to generate music at all. Rather, you can’t use them to generate music with any real level of intentionality or specificity. I don’t think they’ll democratize music creation in the way that they might democratize visual/digital art creation. It’s hard to imagine a universe where somebody who is not already a musician—but can perhaps imagine a piece of music in their head that they’d like to create—can communicate that idea in natural language and have their song come to life via an LLM.
Ultimately, this ends up having little to do with LLMs and more to do with natural language itself and its ability to accurately describe or relate various kinds of perception.
Let’s try to be rigorous
Few people will contest the idea that you can more or less perfectly capture specific sights and sounds with an infinitely long description. At a certain point, you can just state the precise arrangement of the pixels, atoms, wavelengths, etc. Of course, you would never do this, but it serves to illustrate that the descriptive power of language at its limits just isn’t that surprising or interesting. But what does the behavior look like before the asymptote?
Foremost, what we’re really interested in here is a formal measure of “precision” or “intentionality.” How do we know how “good” a description is? Here’s one proposal for such a measure: suppose you have some bijective function between an input space (language) and an output space (sound or sight). Select a point in language space (your description) and use your function to map it to a point in the output space (a sound). Then, select all points in the output space within some small epsilon of the originally obtained point, and use your function to map them back into language space.1 What does the distribution or variance of these obtained points in the input space look like? Or, more concisely, how large is something like:
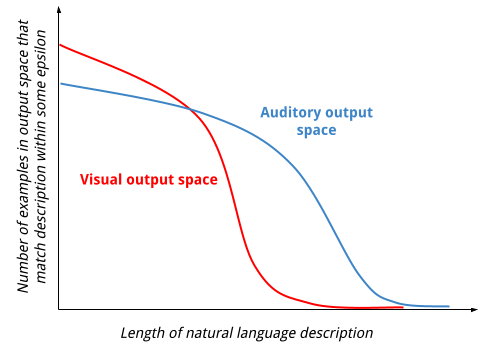
You’d probably want to include some normalizing terms to make this measure a bit more meaningful for comparison, but I think this gets the idea across. As indicated by Figure 1—if this measure is high, it might suggest that similar sounds can be captured with very different descriptions. Similarly, if this measure is high when computed over the inverse of f, it might suggest that very different sounds can be captured by very similar descriptions.
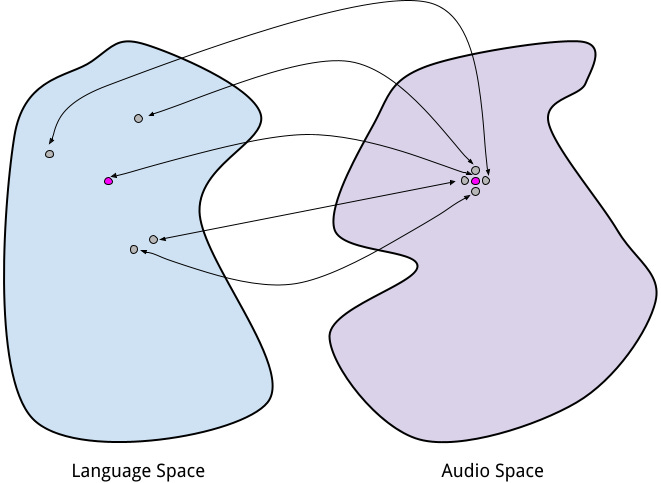
This measure being high in either direction is pretty sad in the context of generative AI. However, very different sounds being mapped to by similar descriptions would bode especially poorly. In such an instance, the maximum likelihood estimation outcome would be to learn whatever mapping outputs the blandest, averaged-over, measure-of-center-y sounds imaginable. And, in doing so, such a mapping jettisons any creativity or intentionality (although it might be great at capturing “vibes”… and I don’t doubt that music-generating LLMs can do that). The average of the “all-human-content-ever” distribution is probably pretty uninteresting; all the great stuff is in the tails!23
Computing such a metric in a meaningful way, e.g. using real models, would probably be pretty and hard expensive, but interesting. This is just a blog post, so, like any rigorous scientist, I’ll just go ahead and provide a photo of what I think the results might look like.
Perception: Global and Local
How we perceive is core to all of this. It’s not like we’re just talking about unstructured pixels and sounds—we’re talking about music and art (I can only write so much about the variance of audio pre-images without feeling like a geeky philistine).
What does it mean for a neighborhood of songs or images to have high variance? What does it even mean for two songs to differ? Let’s ignore the math and only think about good old qualitative perception.
Fundamentally, auditory and visual art are pleasant because of their structure. There’s micro-structure: specific patterns of notes, or the way that short brushstrokes might blend together on a canvas. There’s also macro-structure: the “feeling” or “mood” of a song, or the composition or message of a painting.
I’d posit that capturing micro-structure of any art form in natural language is baseline pretty challenging. You’re probably not going to have DALL-E generate a painting brushstroke by brushstroke. And, if you wanted Suno to generate a song note-by-note, well, then you could just write the sheet music (which doesn’t require physical training in the way that executing desired brushstrokes might).
For either sight or sound, capturing macro-structure in natural language is considerably easier. When speaking with a generative model, you can say something like “generate a surrealist painting of a man wearing a blue suit with black pants, sitting on a partially burnt log in a redwood forest.” Similarly, in the case of generative music, you might say something like “generate a piano piece that starts with a gentle, happy rhythm and crescendos into a gloomy, muddled melody.” Either of these would work just fine. The micro-structure isn’t going away—it’s just left as an exercise to the model.
Unfortunately, I suspect that specific control of microstructure is quite a bit more important for intentionality in sound than it is for sight. That perfect sequence of three notes, followed by a key change, can have an intense emotional effect on you. Can you say the same for three perfectly executed brushstrokes (not to undermine their impressiveness)? Perhaps things were different when painting was more a matter of showing off technical mastery, but people don’t quite receive visual art that way anymore.
Regardless, this is a hard thing to prove. However, it feels natural when you think about the process of listening to a song versus observing a painting. We listen to the song as a time series, sound by sound. You anchor a sound to its neighbors (the microstructure)—there’s no concept of listening to a song “all at once.” Visual art, however, need not be enjoyed in series. Your eyes can dart from corner to corner, alternating between subtle details and broad themes. Music forces you to dwell on microstructure; visual art does not.4
To illustrate this effect, I’ve created two rough “neighbor swapping” experiments. The procedure is simple enough: we decompose art into smaller units and probabilistically shuffle the units around. What happens as the units get bigger?
As Figure 3 demonstrates, we can shuffle neighboring pixels without anything being lost (top right corner). Even shuffling slightly larger rectangles maintains the integrity of the image, despite the micro-structure being substantially altered or even erased. It isn’t until we shuffle large rectangles containing macroscopic features like hands and ears that things start to actually look wonky.




In the recording below, we perform the same exercise with Beethoven’s Für Elise. The first sample is the unaltered piece. The second sample probabilistically swaps neighboring notes, the third sample probabilistically swaps neighboring measures, and the fourth sample probabilistically swaps the first and second halves of the piece. Unlike the procedure applied to the Mona Lisa, the small, micro-structure alterations have the largest effect on the listening experience and intentionality of the piece. Flipping the halves of the piece doesn’t really change the listening experience much, except for the discontinuity in the middle.
Maybe you disagree (especially if you’re a visual artist) and maintain that macro-structure and micro-structure are equally important for intentional creation of sight and sound. Even so, it’s much easier to iteratively refine visual micro-structure in natural language. You can very concisely drill into specific parts of the image and request the changes e.g. “in the upper left quadrant, rather than her hair flowing to the right, please make it flow to the left and be slightly more curly.” I’m not sure how to do the equivalent for music. Sure, you could request something like “change triplet at the beginning of measure 32 to a C# quarter note,” but, if you know what those things mean, why aren’t you just using some score-editing software like Musescore?
Less about language, more about us
You’ll notice that I always take care to clarify the limitations of natural langauge. I do this because there is a language that’s great for concisely describing sounds—the language of music theory.
But why might natural languages like English fall short when it comes to describing sounds versus visuals? I doubt that this is an innate feature of natural languages, but rather a consequence of human preferences. Humans are probably just more prone to describe a thing they’ve seen rather than a thing they’ve heard, and so language has evolved to work incredibly well for the former and so-so for the latter. Maybe we emotionally relate to sights more—or maybe we just encounter them more often (especially in the pre-industrial world, where hearing structured sound was a revered, reserved occasion).
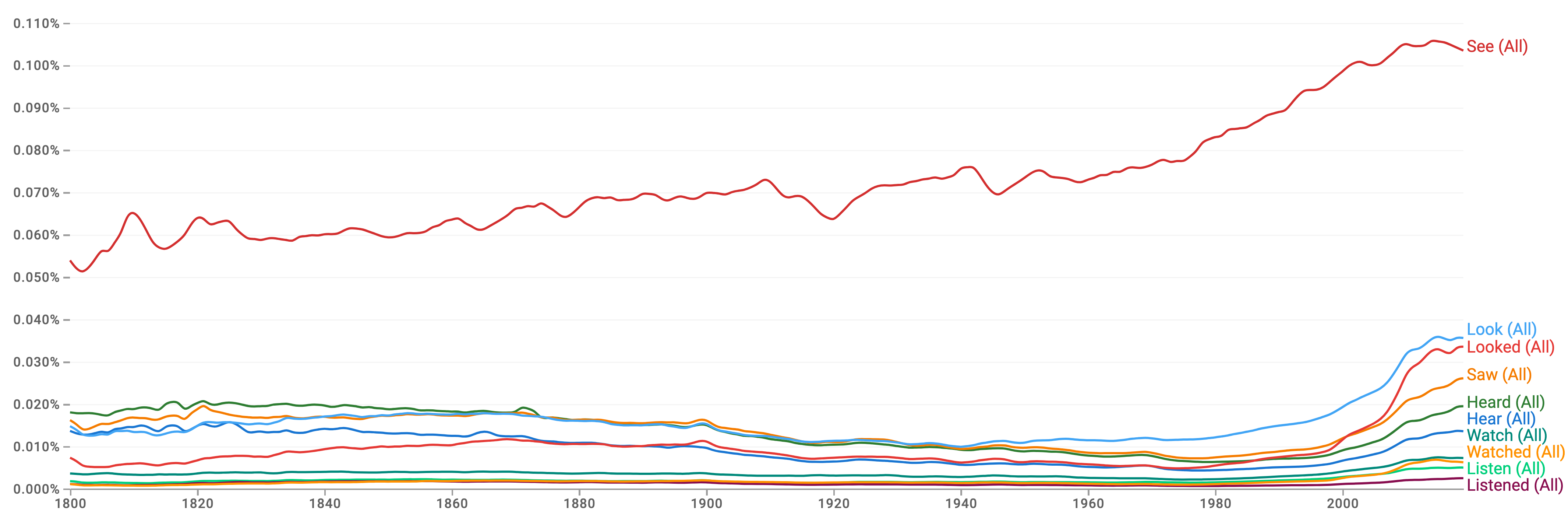
Word frequencies in Figure 4 seem to support this, with all cases of “see” or “look” being used more frequently than the corresponding cases of “hear” or “listen” in recent times (note that the less common “watch” is used less frequently than “hear,” although still more commonly than the analogous “listen”). Interestingly, you can observed that usage of “saw” and “heard” didn’t really diverge until the 1980s, perhaps indicating that the strong present preference for visual-ness is a recent and possibly technology-driven phenomenon (but this is very speculative).
The frequencies of various adjectives (Figure 5) are less clearly convincing, although one might still argue that “dark” and “bright” are used more frequently than the corresponding “quiet” and “loud” respectively (as well as “visual” being used far more often than “auditory”.)

Parting Thoughts
Although pretty speculative, I hope this offered an interesting if concise glance into some of the questions raised by audio-generating AI. It’d be wonderful for there to be more rigorous research conducted in this direction; I suspect there are pretty interesting applications, especially in the context of low and high resource languages and/or translation (How intentional can somebody be in language X if translating from language Y? What if we translate from Y to A to X?)
And finally, for the people making these music-generating apps: they’re fascinating and impressive, but maybe natural language isn’t the right medium here. What if, instead, we mapped sound to sound, creating music by humming melodies and accompanying them with supplementary natural language descriptions when necessary (“this should be played by a violin, make it gloomy”). Now, that’d be pretty cool.
Thanks to Lucy for chatting with me about these topics for a few hours!
If you’re getting flashbacks to your undergraduate analysis class… yeah, me too.
Of course, model builders are very clever, and it’s not like they’re running a naive MLE and calling it a day. You can probably massage a lot of these problems out with clever objective function design and RLHF.
This reminds me of the alignment versus creativity debate. The most “aligned” model is probably one that does the measure-of-center-y output, but the most “creative” model is the one that does the opposite. How might one balance this? Who knows!
Except for, you know, movies.